Quantifying the uncertainty in agent-based models
Josie McCulloch, Alison Heppenstall and Nick Malleson
Universities of Leeds & Glasgow, and the Alan Turing Institute, UK
Slides available at:
https://urban-analytics.github.io/dust/presentations.html
![]()
![]()
![]()
![]()
Abstract
Agent-based modelling is maturing as a method for capturing and simulating individual behaviour and activity. Whilst there are a dazzling array of applications appearing in the literature, there is less work that focuses on important methodological issues such as the handling of uncertainty in these models. We discuss (and demonstrate) how approaches from the field of Uncertainty Quantification can be adapted for use in agent-based models so that models can become robust enough to be used in important policy decisions.
Acknowledgements
Josie McCulloch, Patricia Ternes, Robert Clay,
Jiaqi Ge, Jonathan Ward, Minh Kieu
Greetings from Yorkshire

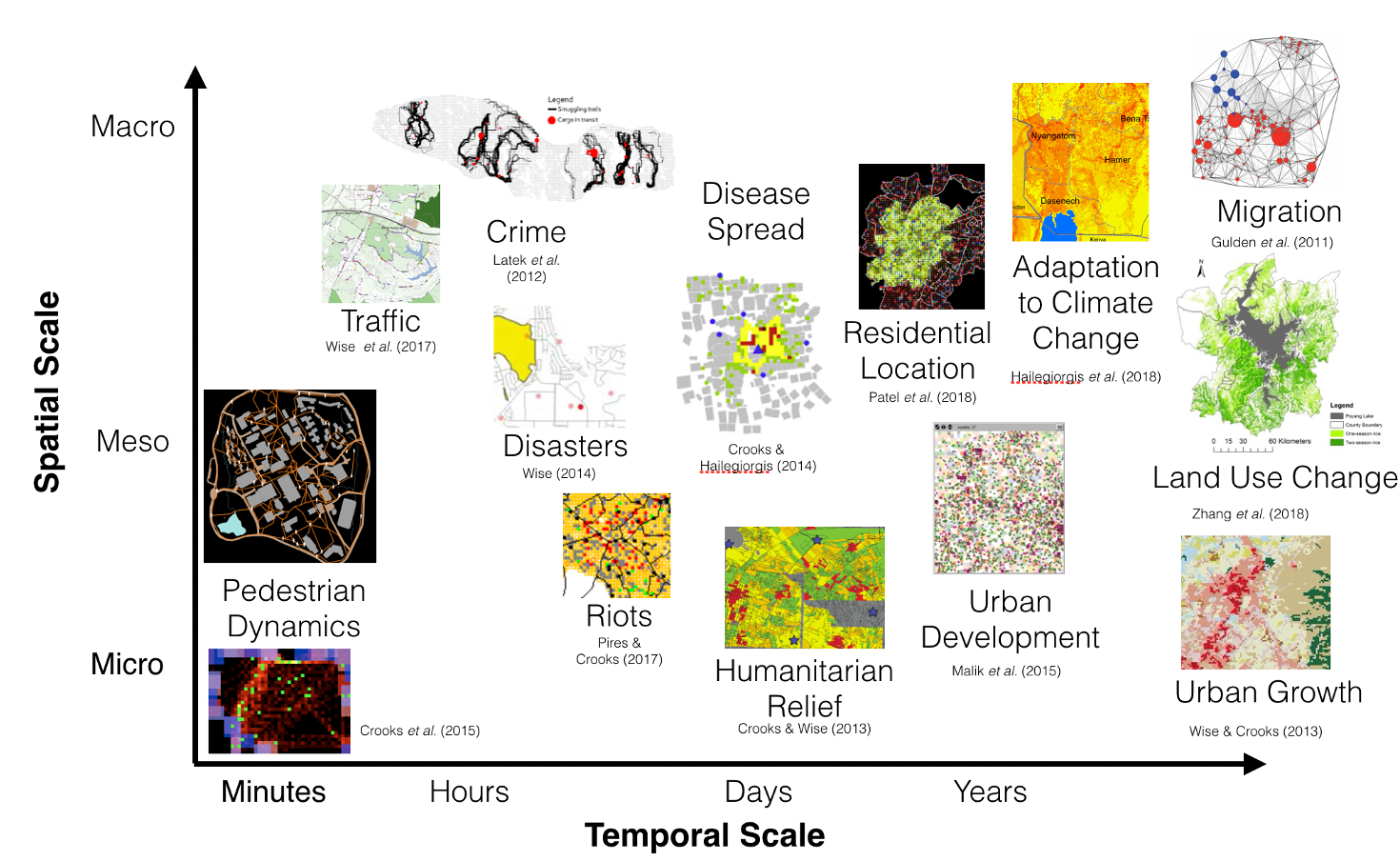
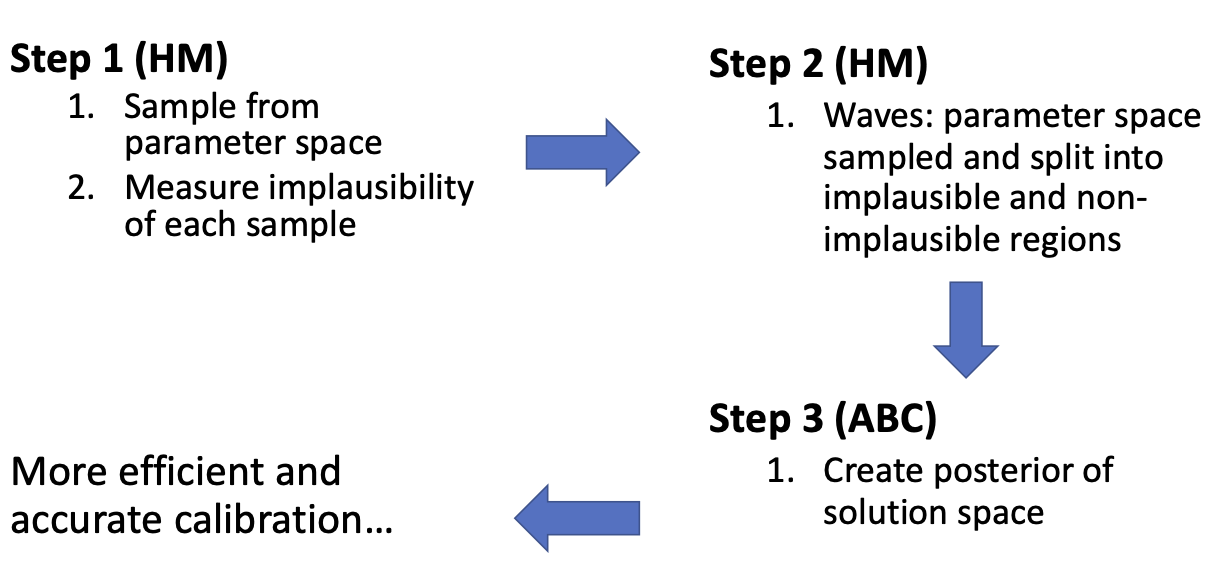
Talk overview
Why is ABM and calibration difficult?
Why should we bother?
First steps into UQ
Adding a time dimension
Towards live simulations
Agent-Based Modelling
Systems are driven by individuals
(cars, people, ants, trees, whatever)
Individual-level modelling
Rather than controlling from the top, try to represent the individuals
Autonomous, interacting agents
Situated in a virtual environment

Calibration
Finding the optima not a problem, finding the global is…
Model discrepancy – error between optimised error and an observation
Uncertainties – between model and real system
Computational cost: potentially lots of parameters = lots of runs
And added delights with ABM...
Nature of the system
Variable dimensionality
Distance metric based on pattern measurement
Emulation of model structure with many different rules
ABM and Uncertainty
Parameter uncertainty:
Which parameters? Which values? Equifinality.
Observation uncertainty
Imprecise, noisy data, natural variability
Model uncertainty / model discrepancy:
Model is a simplification (relies on assumptions and imperfections)
Ensemble variance:
Stochastic variance
Uncertainty Quantification
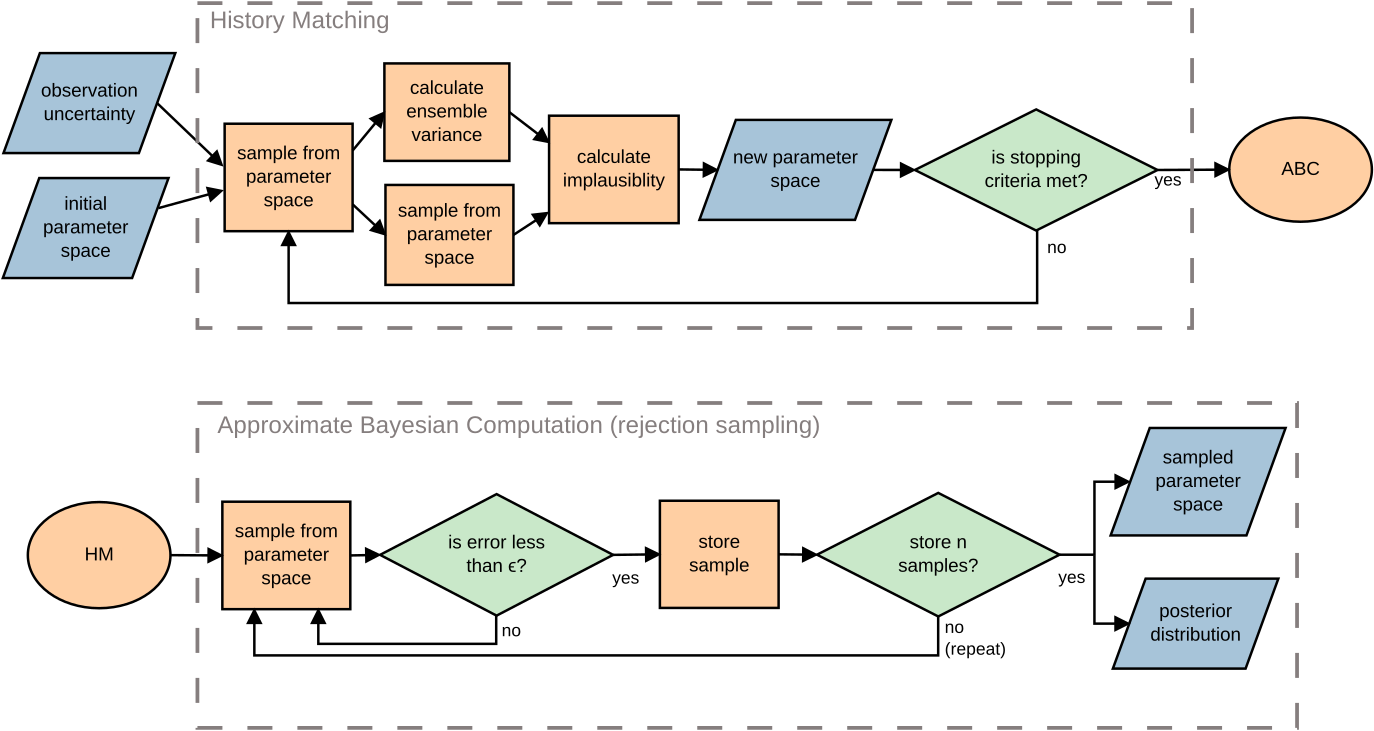
History Matching (HM)
HM is a procedure used to reduce the size of the parameter space (Craig et al. 1997)
HM discards areas found to be implausible, leaving a (usually) much smaller non-implausible region of inputs
Approximate Bayesian Computation (ABC)
ABC estimates a posterior distribution that quantifies the probability of specific parameter values given the observed data
Combined ...
Combined ...
Sugarscape

Here we are looking at two parameters:
Maximum possible metabolism of an agent
Maximum possible vision of an agent
Outcome measure is size of population that the model can sustain (66).
Framework followed
Define the parameter space to be explored
Quantify all uncertainties in the model and observation
Run HM on the parameter space
Run ABC, using the HM results as a prior
Sugarscape: HM
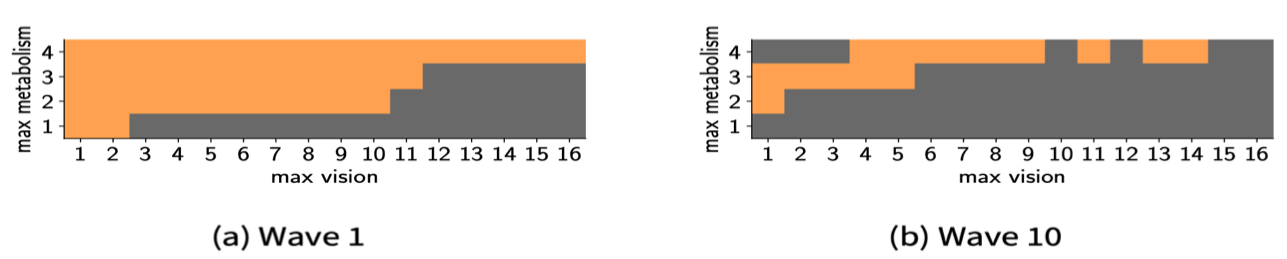
Sugarscape - small parameter space. Measure the implausibility of each parameter pair (metabolism, vision)
10 waves performed – use plausible space from wave 1 as input to wave 2 and so forth
Sugarscape: ABC
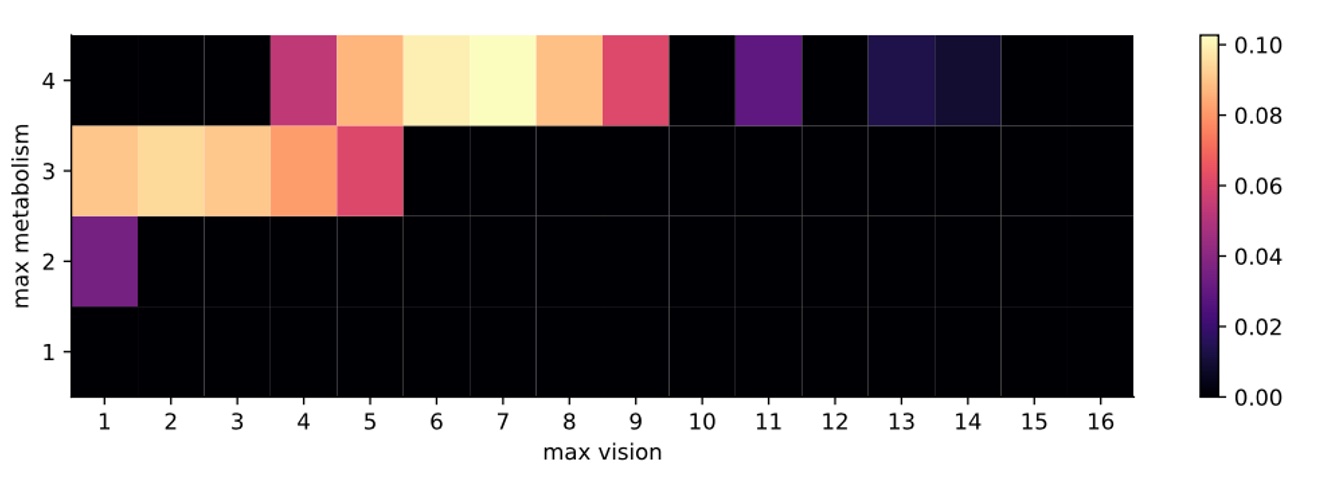
Results show that the parameters with the highest probability of matching the observation (i.e. sustaining a population of 66 agents) are where {metabolism, vision} are {4, 7}.
Next steps: History Matching and ABC
Framework applied to two empirical models
Movements of territorial birds (Thiele et al. 2014)
Brexit-related changes in Scottish cattle farms (Ge et al, 2018)
HM reduces the number of model runs required compared to using ABC alone and leads to a narrower posterior.
ABC posterior provides much more information than a single optimal parameter point estimate
.. paper currently in review ..
Rapid Assistance in Modelling the Pandemic (RAMP): Urban Analytics
Microsimulation of disease spread
Includes shopping, schooling, working
Calibrated on hospital admissions data

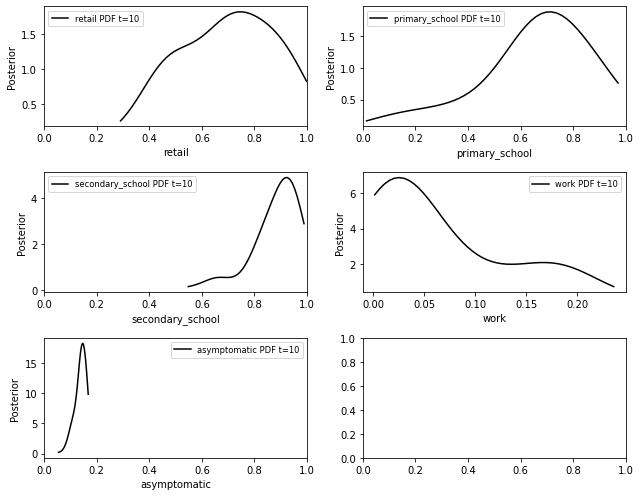
RAMP: Urban Analytics
ABC Parameter posteriors
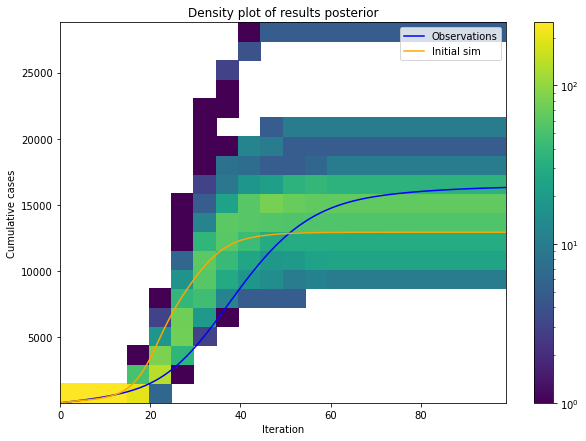
RAMP: Urban Analytics
ABC results uncertainty
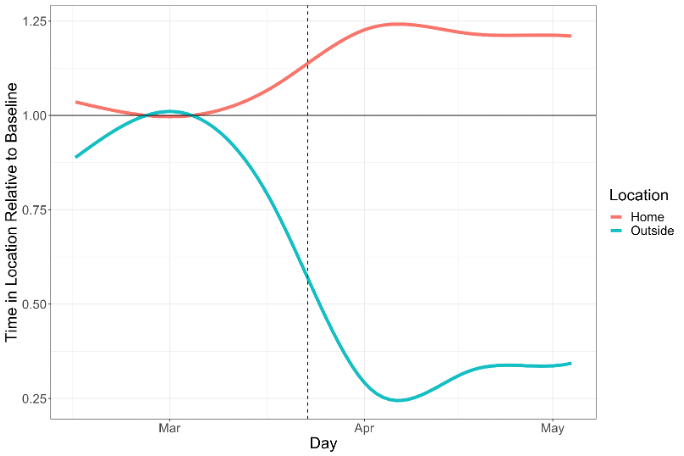
Reducing Uncertainty in Real Time
Example: Urban Mobility
People are the drivers of processes in cities
We need to understand mobility patterns:
Pollution – who is being exposed? Where are the hotspots?
Economy – can we attract more people to our city centres?
Disease - which times / places have large numbers of interactions
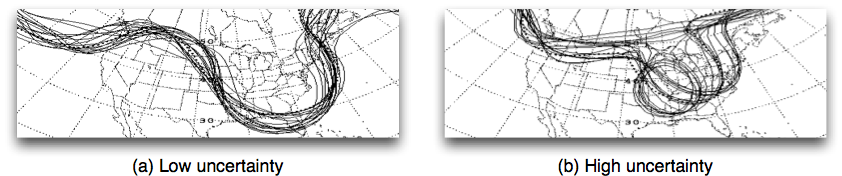
Problem: Models will Diverge
Lots of uncertainties
Inputs (measurement noise)
Parameter values
Model structure
Natural stochasticity
... and that's assuming that the system hasn't changed fundamentally
Possible Solution: Data Assimilation
Used in meteorology and hydrology to update running models with new data.
Try to improve estimates of the true system state by combining:
Noisy, real-world observations
Model estimates of the system state
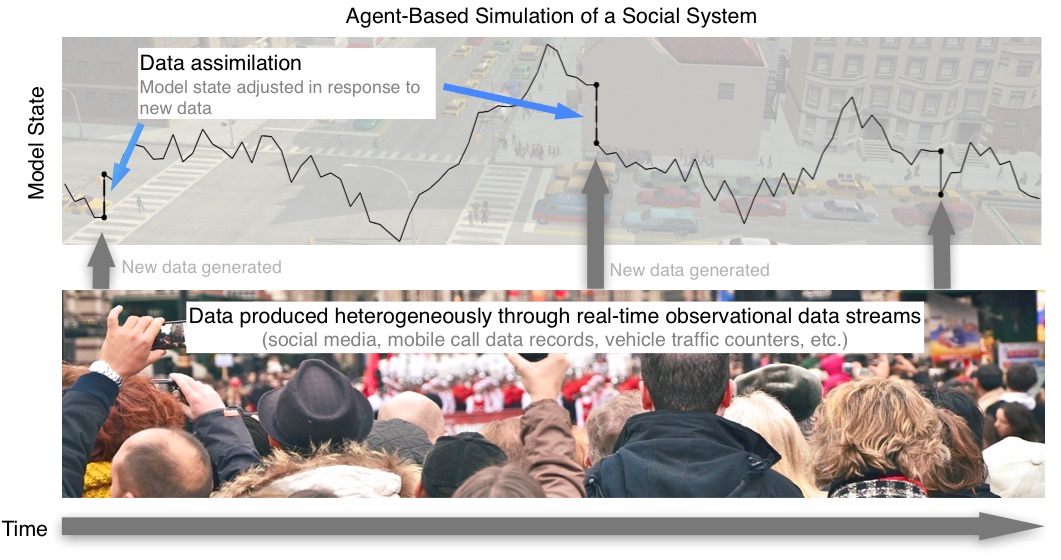
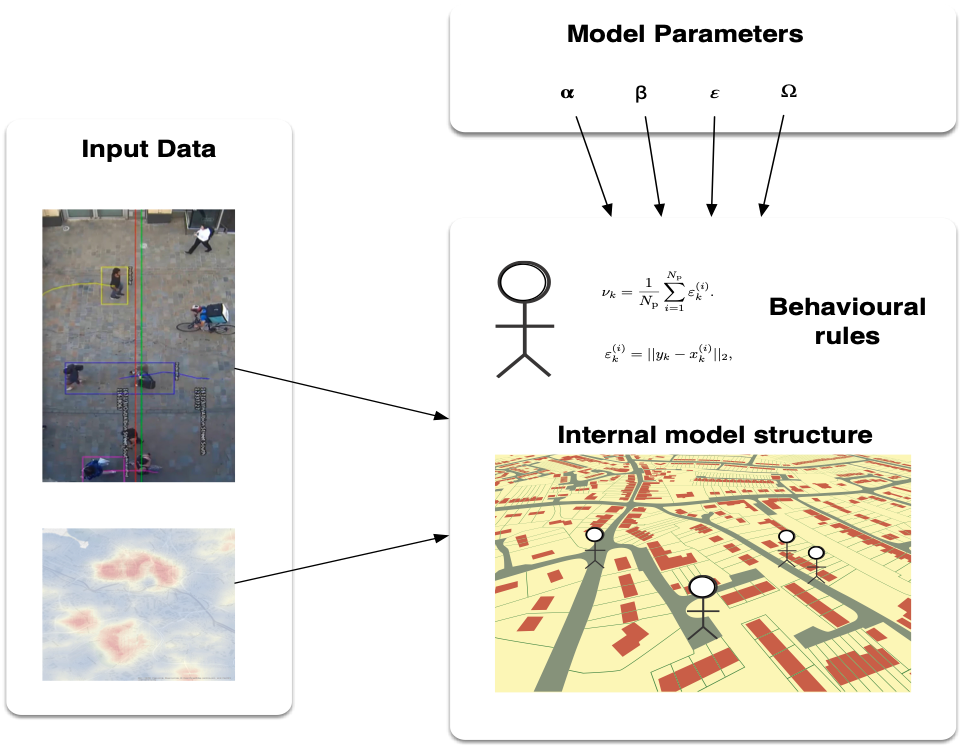
Example: Real Time Crowd Modelling
Simulating a city in real-time is too hard!! (for now). Let's start with a crowd
Can we reduce the uncertainty in an agent-based crowd simulation in real time?
Pedestrian trace data (Grand Central Terminal, New York City)
B. Zhou, X. Wang and X. Tang. (2012) Understanding Collective Crowd Behaviors: Learning a Mixture Model of Dynamic Pedestrian-Agents. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2012
Data assimilation with a Particle Filter
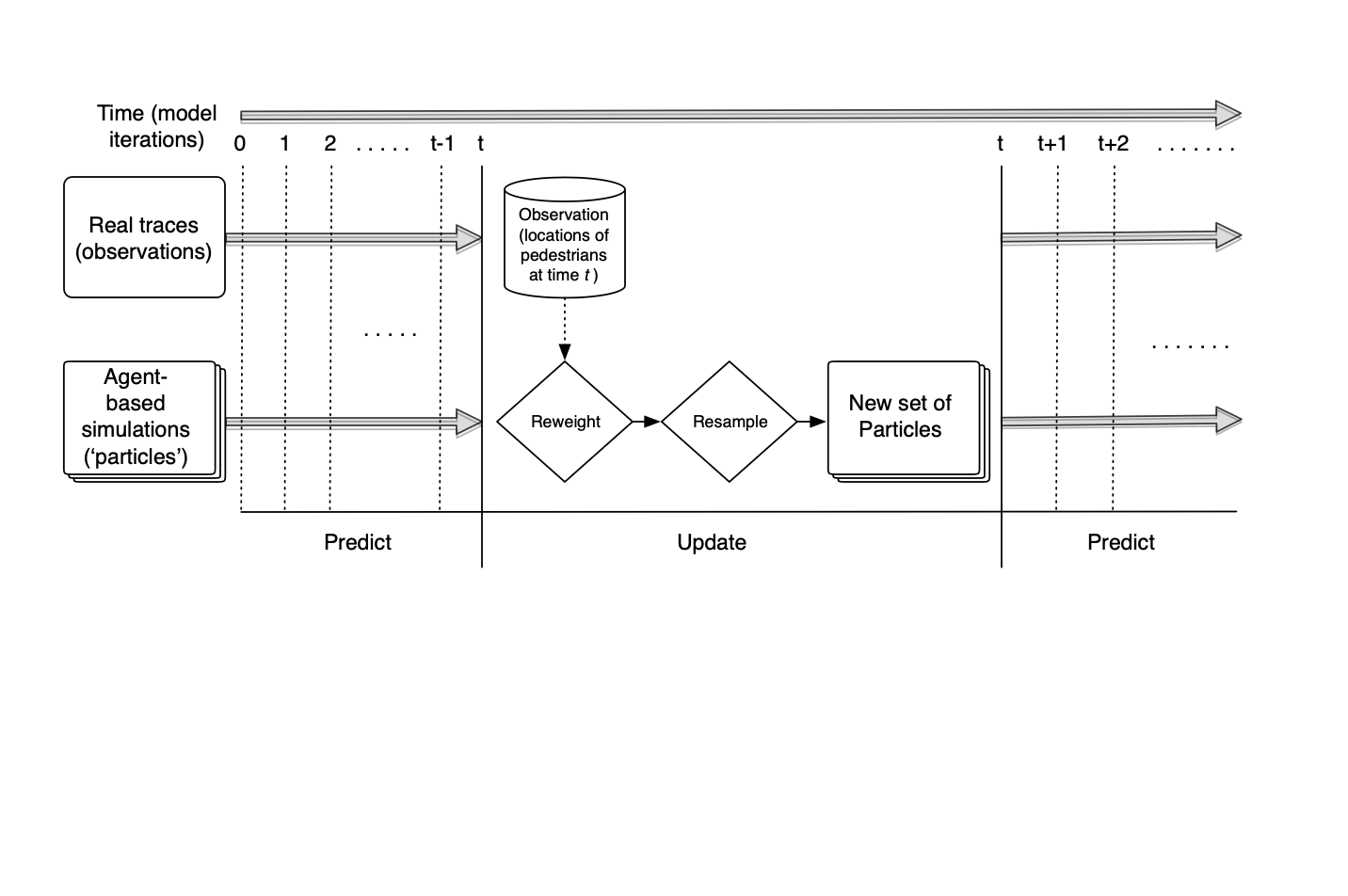
Particle Filter Results
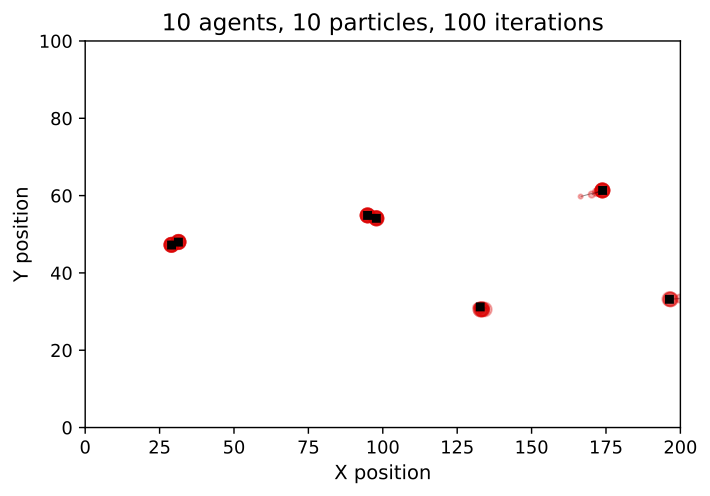
Particle Filter Results
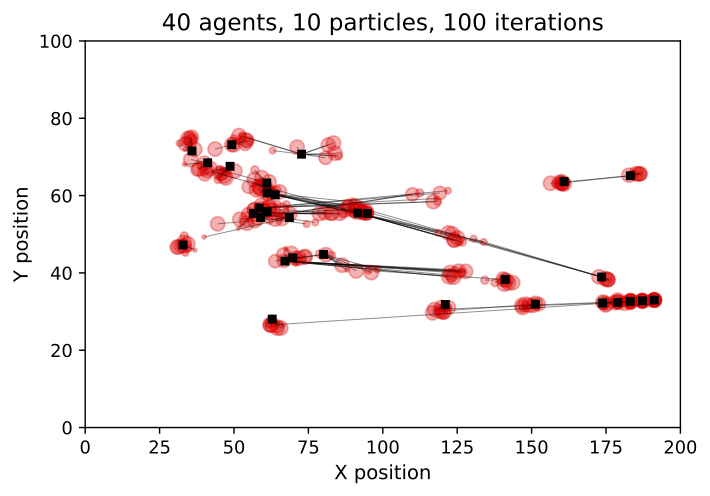
Preliminary Particle Filter Results
Box Environment: More particles = lower error
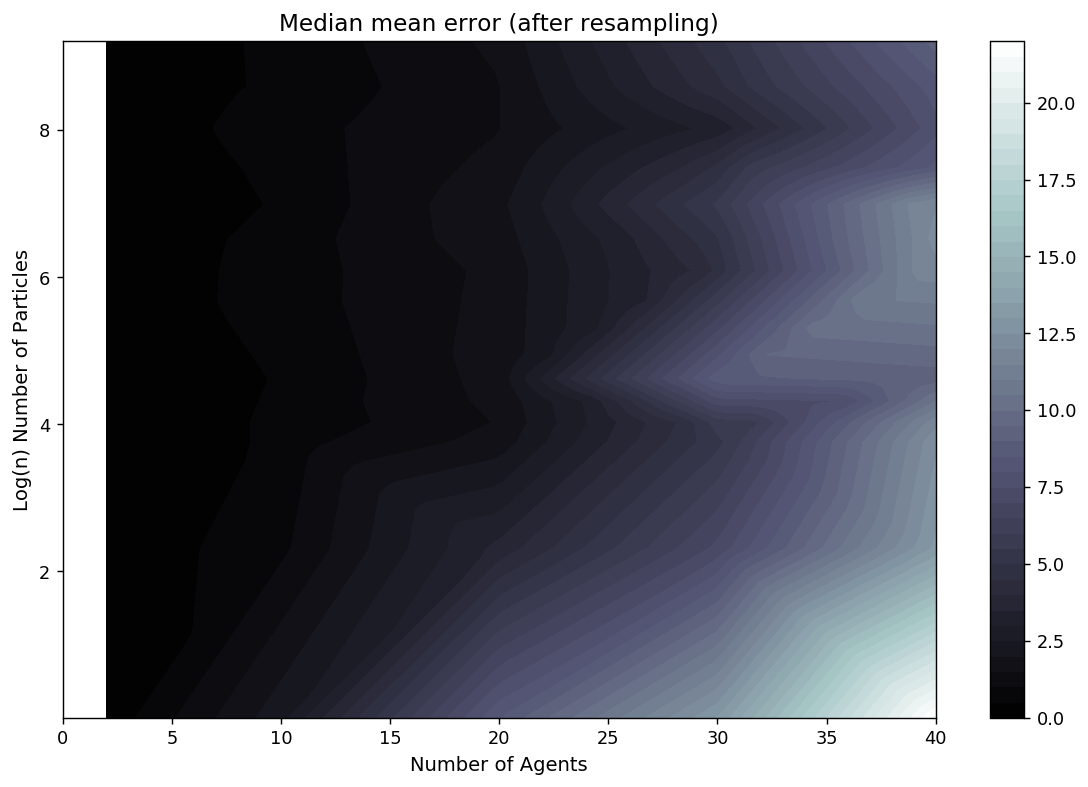
Difficulties (I)
Exponential increase in complexity
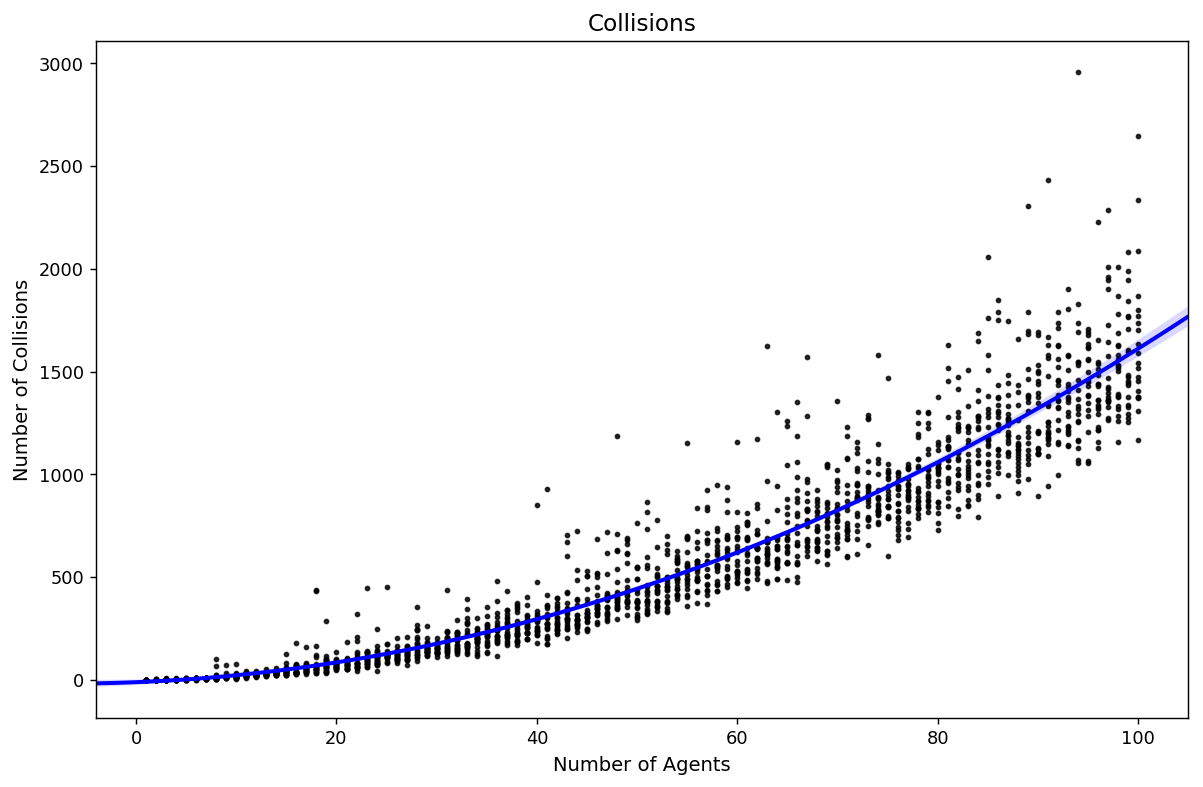
Solutions (I)

More particles!
Will need high performance computing, but we have lots of that
Better PF algorithms (we used the most basic)
Alternative data assimilation methods
More advanced particle filtering is available
Unscented / Ensemble Kalman Filters
Solutions (I)
Unscented Kalman Filter
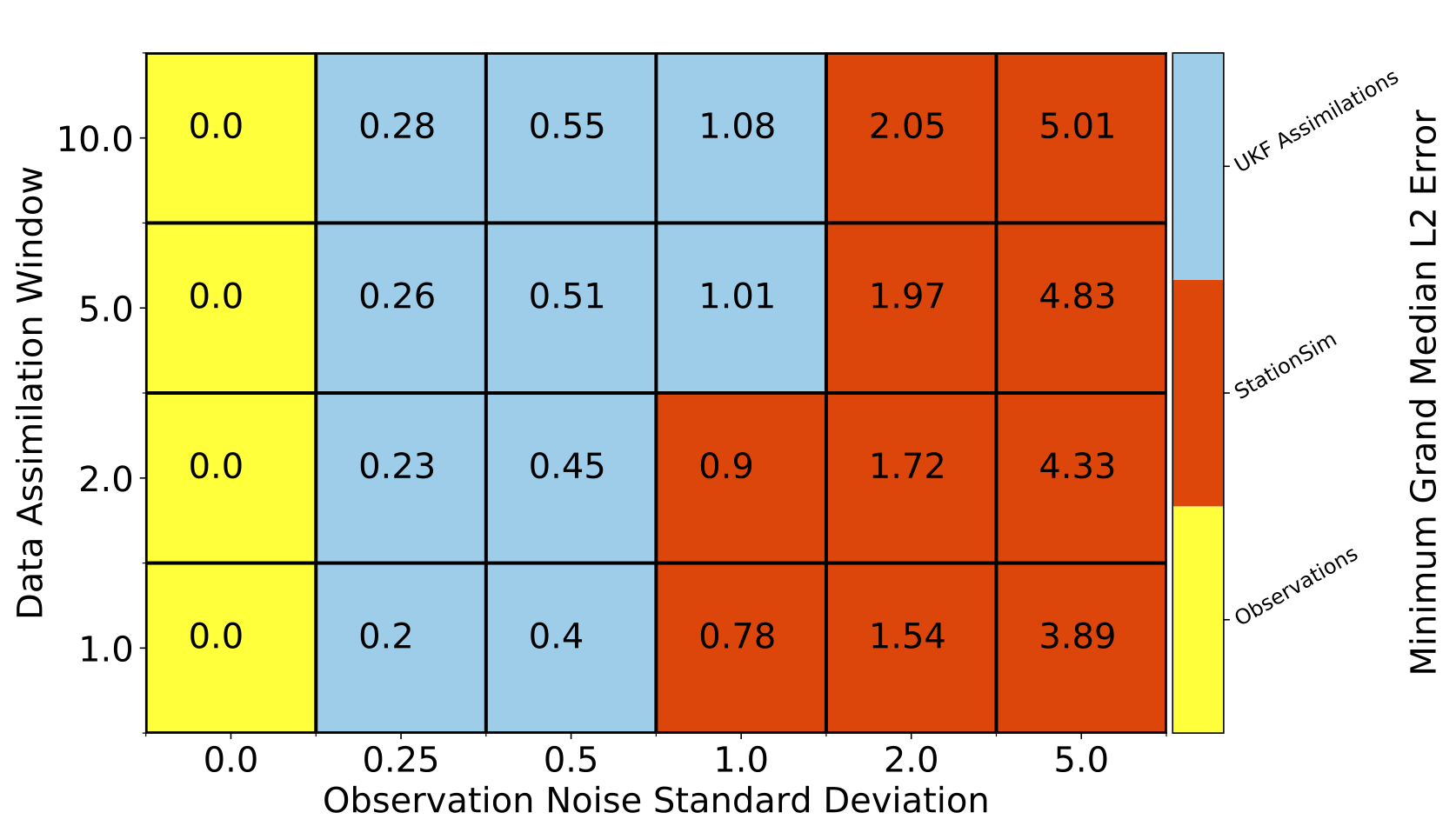
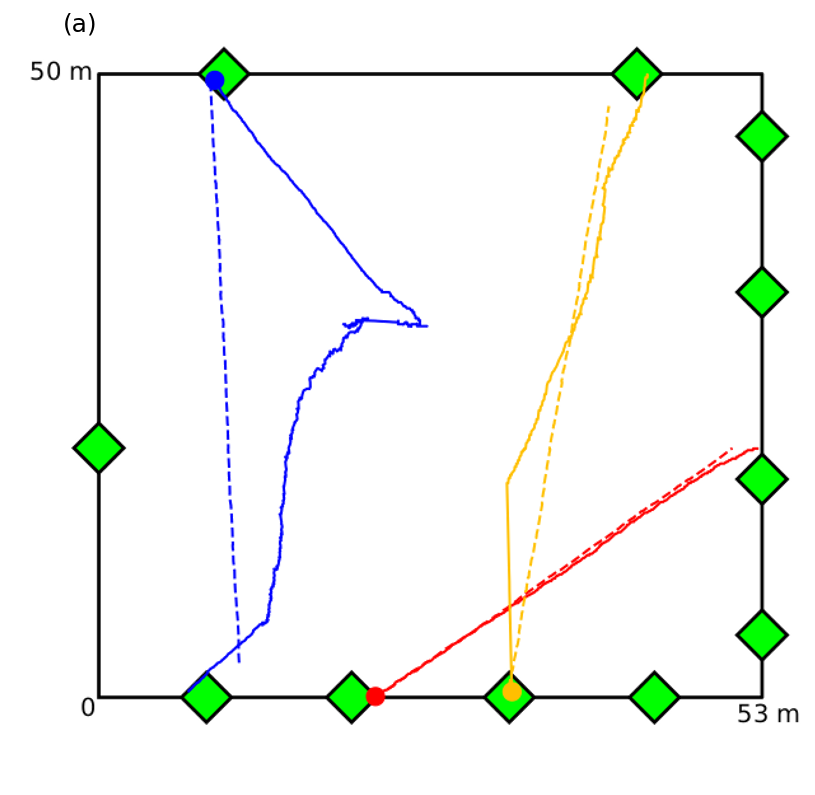
Difficulties (II)
Model Discrepancy
Some behaviours are more predictable than others
No obvious 'solution' to this
But shows how important data assimilation could be
Other Methods (ongoing)
Ensemble Kalman Filter
Ward, Jonathan A., Andrew J. Evans, and Nicolas S. Malleson. (2016) Dynamic Calibration of Agent-Based Models Using Data Assimilation. Royal Society Open Science 3(4). DOI: 10.1098/rsos.150703.
Unscented Kalman Filter
Clay, Robert, Le-Minh Kieu, Jonathan A. Ward, Alison Heppenstall, and Nick Malleson (2020) Towards Real-Time Crowd Simulation Under Uncertainty Using an Agent-Based Model and an Unscented Kalman Filter’. In Advances in Practical Applications of Agents, Multi-Agent Systems, and Trustworthiness. The PAAMS Collection 12092:68–79. Lecture Notes in Computer Science. DOI:10.1007/978-3-030-49778-1_6.
Quantum Field Theory - Creation and Annihilation Operators
Tang, Daniel. (2019) Data Assimilation in Agent-Based Models Using Creation and Annihilation Operators. ArXiv:1910.09442 [Cs]. arxiv.org/abs/1910.09442.
Ethical Implications
Data Bias
Need to be very careful: biased data -> biased models
The digital divide
Tracking People
Advantage with these methods is we don't need to track people
Models work with counts of flows
Although may need work on mapping from the data to the model domain (e.g. Lueck at al. (2019))
Related Projects
Data Assimilation for Agent-Based Models (DUST)
Uncertainty in agent-based models for smart city forecasts
Bringing the social city to the smart city
Summary - Towards Live* Simulations
Potential for large-scale, agent-based models to transform policy making
Pollution, economy, disease spread, ...
But need to better understand the uncertainty in our models
What do we need?
Uncertainty quantification for ABMs
Efficient data assimilation methods for ABMs
High-resolution data (the identifiability problem)
Better models ?
*Swarup, S., and H. S. Mortveit (2020) Live Simulations. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, 1721–25.
Quantifying the uncertainty in agent-based models
Josie McCulloch, Alison Heppenstall and Nick Malleson
Universities of Leeds & Glasgow, and the Alan Turing Institute, UK
Slides available at:
https://urban-analytics.github.io/dust/presentations.html
![]()
![]()
![]()
![]()